在當今數據驅動的時代,大數據技術已成為企業數字化轉型的關鍵引擎。許多求職者或從業者在簡歷上標榜“大數據專家”,卻對Hadoop這一基礎框架知之甚少,這不禁讓人質疑其專業深度。Hadoop作為分布式系統領域的里程碑,不僅是數據處理與存儲服務的核心,更是大數據生態的根基。
Hadoop解決了海量數據存儲與計算的瓶頸。其分布式文件系統HDFS允許數據跨多臺機器存儲,提供高容錯性;而MapReduce編程模型則實現了并行處理,使TB級數據的分析成為可能。例如,電商平臺通過Hadoop集群分析用戶行為日志,優化推薦算法;金融機構利用它進行風險建模,處理實時交易流。若缺乏Hadoop知識,如何設計可擴展的數據管道?又怎能理解數據分片、副本機制等關鍵概念?
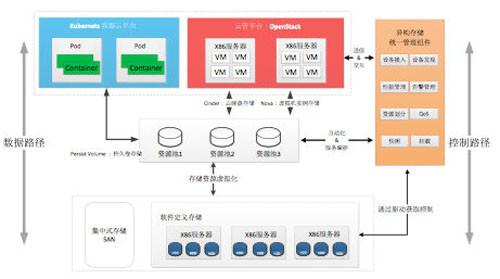
Hadoop生態圈衍生出眾多工具,如Hive用于SQL查詢、HBase支持實時讀寫,這些共同構成了完整的數據服務架構。一名合格的大數據工程師需熟悉Hadoop組件間的協同,例如用Sqoop從關系數據庫導入數據至HDFS,再通過Spark進行高效計算。忽略Hadoop,無異于搭建高樓卻忽視地基——可能短期內依賴云服務暫避復雜性,但長遠來看,無法深入優化性能與成本。
更重要的是,Hadoop所代表的分布式思想是應對數據爆炸的基石。隨著5G和物聯網發展,數據量呈指數增長,企業需自建或管理混合云環境來保障數據主權與安全。Hadoop的開源特性及社區支持,使其成為定制化解決方案的首選。例如,醫療行業利用Hadoop存儲基因組數據,確保合規的同時加速研究進程。
技術日新月異,云原生工具如Snowflake、Databricks逐漸興起,但它們的底層邏輯常借鑒Hadoop的分布式理念。真正的大數據從業者應掌握Hadoop原理,方能靈活適配新技術。求職者若僅停留在API調用層面,而未深入Hadoop的架構設計,恐難在數據洪流中站穩腳跟。
Hadoop不僅是技術符號,更是大數據能力的試金石。在數據處理與存儲服務領域,與其浮于表面追逐熱詞,不如夯實基礎,從Hadoop出發,構建抵御數據浪潮的真實壁壘。