隨著企業數字化轉型的深入,數據已成為核心資產。在這一背景下,云原生數據中臺應運而生,它不僅是技術的集合,更是企業數據能力的新型中樞。本文將從What(是什么)、Why(為什么)、Who(誰需要)、How(如何構建)和Where(應用場景)五個維度,深入解析云原生數據中臺的數據處理與存儲服務。
一、What:云原生數據中臺是什么?
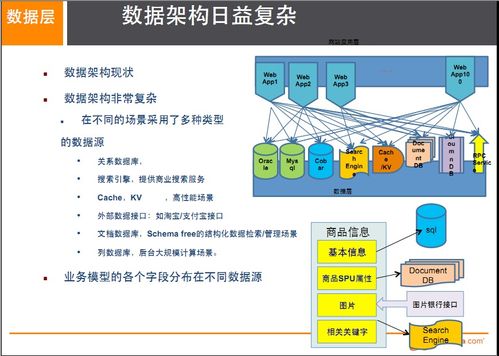
云原生數據中臺是一套構建在云平臺之上、采用云原生技術棧(如容器、微服務、DevOps)的數據能力平臺。它通過統一的數據處理與存儲服務,將企業內外部多源異構數據進行采集、治理、整合、分析與服務化,形成可復用、可共享的數據資產中心。其核心在于以數據服務的形式,敏捷、彈性地支撐前端業務快速創新。
二、Why:為什么需要云原生數據中臺?
傳統數據架構常面臨煙囪式建設、數據孤島、響應遲緩、擴展成本高等挑戰。云原生數據中臺通過以下方式解決這些問題:
- 敏捷與彈性:利用云的彈性伸縮和容器化部署,快速響應業務變化,資源按需分配。
- 統一與復用:構建標準化的數據處理流水線和數據模型,避免重復開發,提升數據一致性。
- 降本增效:采用Serverless、存算分離等技術,優化資源利用率,降低運維復雜度。
- 創新驅動:為業務部門提供自助式數據服務,加速數據分析、AI應用等創新場景落地。
三、Who:誰需要云原生數據中臺?
云原生數據中臺適用于多類組織:
1. 大型企業:業務線復雜、數據量龐大,需打破部門墻,實現數據互聯互通。
2. 互聯網與科技公司:追求快速迭代,需要彈性、高可用的數據基礎設施支持產品創新。
3. 數字化轉型中的傳統行業:如金融、零售、制造等,希望通過數據驅動運營與決策。
4. 數據密集型機構:如研究機構、政府部門,需高效處理和分析海量數據。
關鍵角色包括數據團隊(工程師、分析師)、業務部門及決策層,他們共同依賴中臺獲得數據能力。
四、How:如何構建云原生數據中臺的數據處理與存儲服務?
構建過程需循序漸進,結合組織實際:
- 技術選型:采用Kubernetes進行容器編排,選用云原生數據組件(如Apache Kafka用于流處理、對象存儲服務等),并考慮多云或混合云部署。
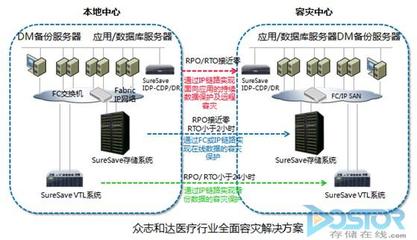
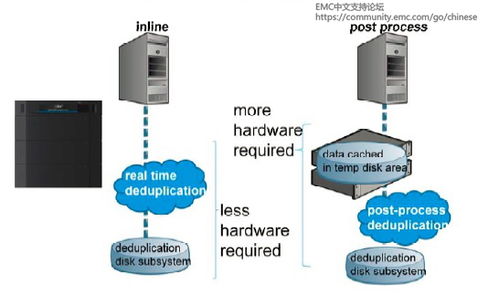
- 架構設計:實施分層架構,包括數據采集層、存儲層(冷熱數據分層)、計算層(批流一體)、服務層(API化數據服務)與管理層(數據治理、安全監控)。
- 數據治理:建立數據標準、質量規則與元數據管理,確保數據可信可用。
- 文化流程:推行DataOps,實現數據開發與運維的自動化協作;培養數據思維,促進業務與技術的融合。
五、Where:數據處理與存儲服務的應用場景在哪里?
云原生數據中臺的服務廣泛滲透于業務全鏈路:
- 實時分析與決策:如電商實時推薦、金融風控監控,通過流處理服務即時響應數據變化。
- 用戶畫像與個性化:整合多源用戶數據,構建統一畫像,支持精準營銷。
- 智能運營與預測:利用歷史數據訓練AI模型,進行銷量預測、設備預警等。
- 數據產品孵化:快速構建數據API,賦能內部應用或對外提供數據服務。
- 合規與審計:集中存儲與處理日志、交易數據,滿足監管要求。
云原生數據中臺代表了數據基礎設施的演進方向,其數據處理與存儲服務不僅是技術升級,更是組織邁向數據智能的核心支撐。企業需從戰略高度規劃,以小步快跑的方式實施,方能釋放數據價值,贏得數字時代的競爭優勢。隨著云原生生態的成熟,數據中臺將更加智能、自治,成為企業不可或缺的數字神經中樞。